..
读 Cloudflare Outage February 20 2026
假如将故障比做生活中的挫折,它们几乎都是不可避免,但并非完全负面 —— 珍贵的学习与进步机会。这个系列会持续分享各种故障复盘(Postmortem),与大家一起学习进步。
名词解释
- BYOIP(Bring Your Own IP,自带 IP):允许企业将自己拥有的公网 IPv4 或 IPv6 地址段迁移到云服务商的基础设施中使用的服务(BGP 本地宣告 -> 云厂商宣告)。
- BGP(Border Gateway Protocal):互联网的邮政服务。当有人把一封信投进邮筒时,邮政服务就会处理这封邮件,并选择一条快速、高效的路线将这封信投递给收件人。
- BGP Path Hunting:
- 假设你在 AS1(比如中国电信),想访问位于 AS5(比如 Cloudflare)的服务器,可能存在以下几条路径,每个路由器根据路径选择算法选出最优路径。
- 路径 A:
AS1 -> AS2 -> AS5 - 路径 B:
AS1 -> AS3 -> AS4 -> AS5 - 路径 C:
AS1 -> AS2 -> AS3 -> AS5
- 路径 A:
- 最优路径中,假如
AS2 -> AS5链路断了,AS2会向AS1发出撤销消息,告诉它此路不通 AS1收到撤销消息后,告诉AS2可以通过AS3 → AS5到达。AS2收到AS1的通告,发现自己可以绕道走AS2 → AS1 → AS3 → AS5,于是又向外通告这条路径(所有邻居)。- 但
AS1一看,AS2通告的这条路径包含AS1自己(AS Path 里有AS1),按 BGP 规则会拒绝(防环),所以AS1再次撤销,改选路径C(经AS4)… - 结果整个网络里产生了大量的 UPDATE/WITHDRAW 消息,每个路由器都在反复更新路由表,直到最终所有人都稳定在同一条可用路径上,这种反复切换、探索和收敛的过程就是 Path Hunting。可能持续数十秒甚至几分钟。
- 假设你在 AS1(比如中国电信),想访问位于 AS5(比如 Cloudflare)的服务器,可能存在以下几条路径,每个路由器根据路径选择算法选出最优路径。
故障过程
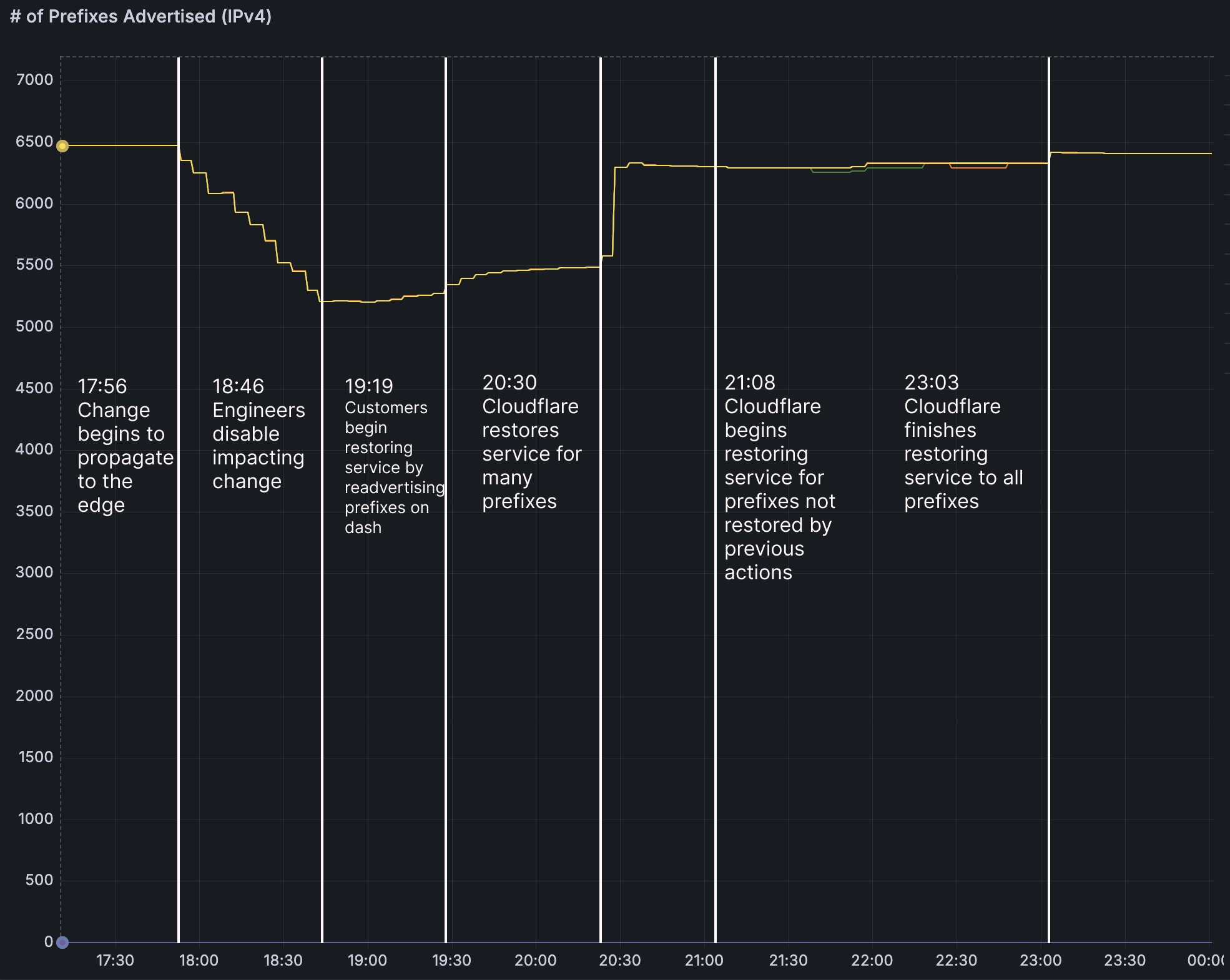
故障一共持续 6 小时 7 分钟,下面是完整的时间线:
- 17:56:变更注入
- 18:46:变更中断
- 19:19:发出通告,部分用户通过控制台手动恢复
- 20:30:变更回滚,开始恢复大部分的受影响用户
- 21:08:开始恢复所有用户(由于 bug 部分前缀被删除,需要手动恢复)
- 23:03:故障完全恢复
⚠️备注1:下图中的指标代表故障期间,Cloudflare 向某个 BGP 邻居节点中宣告的前缀总量(也就是可正常访问的路由前缀数量)。
⚠️备注2:由于 1.1.1.1(one.one.one.one)也收到影响,工程师才意识到问题的严重性,并在 18:46 开始回滚变更。
⚠️备注2:变更没有影响所有用户的原因:变更是分批进行的,在发现用户受影响时,就中止了。
故障原因 & 用户影响
这次故障并非外部恶意攻击,而是一个内部的变更导致:不小心撤回了部分用户的路由前缀(大约 25% ~1,100 个),最终导致他们的 IP 出现完全不可达的情况。
用户影响:
- 首先由于 BGP Path Hunting,请求不会立即失败,而是反复寻找备用路径,试图找到一条能到达最终目标 IP 的路径(想象导航失效的你,像个无头苍蝇一样开车乱转)。但由于 IP 不可达,最终会超时失败,用户的感受是网页请求卡死。
1.1.1.1DNS 解析服务没有受影响,但访问1.1.1.1页面的用户,会出现 HTTP 403 错误(刚好也受影响,前缀被撤回)。
故障根因
本次 6 个小时的故障由于一个“简单”的穿参问题导致。
自动化任务依赖的两个接口:
- 查询“待删除列表”的 GET 接口
- 执行删除
resp, err := d.doRequest(ctx, http.MethodGet, `/v1/prefixes?pending_delete`, nil)
查询接口一个参数引发的血案:
- ✅
?pending_delete=true:API 返回待删除的前缀,正常执行删除动作。 - ❌
?pending_delete(无值):API 返回全量前缀,客户端误以为全部删除,触发了故障。
if v := req.URL.Query().Get("pending_delete"); v != "" {
// ignore other behavior and fetch pending objects from the ip_prefixes_deleted table
prefixes, err := c.RO().IPPrefixes().FetchPrefixesPendingDeletion(ctx)
if err != nil {
api.RenderError(ctx, w, ErrInternalError)
return
}
api.Render(ctx, w, http.StatusOK, renderIPPrefixAPIResponse(prefixes, nil))
return
}
⚠️为什么没有在测试或预发环境中发现这个问题? 1)数据的局限性:无法充分模拟真实场景下的行为。 2)测试覆盖不完整:只覆盖了用户控制台的场景,遗漏了定时任务。
⚠️为什么回滚变更没有立即恢复服务? 个人理解代码可以快速回滚,但数据还是需要人工回滚。文中提到 Cloudflare 拥有状态快照+健康检查自动回滚的能力,可惜还在建设中,未上线 :)
行动项
- API Schema 的标准化(类型约束和参数校验)
- 可回滚:客户的配置维护在一张生产表中,所有生产维护任务也直接读写这张表,两个操作混在一起,最终导致回滚异常困难(手动会滚)。所以需要添加变更的“中间态”(快照 + 健康检查),随时自动回滚。
- 可监控:针对明显异常的变更快速自动中断,进而控制用户影响范围。
其他思考
- 生产环境中,所有「删除」相关的操作都应该谨慎三分。
- 所有故障的根因在复盘时都会显得简单甚至可笑,但人总会犯错误的,我们应该通过变更的灰度、监控、可回滚的机制,在理论上扼杀风险。
- 故障发生后,即使是 blame free,SRE 往往是故障的第一责任人,甚至在用户不可挽回的损失中陷入自责。但如果所谓“建设中”的自动回滚能力在故障发生前上线了,故障被成功避免,幕后英雄则因为人性被默默遗忘。取决于公司文化,大部分大公司的 leadership 还是会将服务可用作为公司“头等大事”,对故障避免的事迹大力嘉奖。